HTTP caching
The performance of web sites and applications can be significantly improved by reusing previously fetched resources. Web caches reduce latency and network traffic and thus lessen the time needed to display resource representations. HTTP caching makes Web sites more responsive.
Types of caches
Caching is a technique that stores a copy of a given resource and serves it back when requested. When a web cache has a requested resource in its store, it intercepts the request and returns a copy of the stored resource instead of redownloading the resource from the originating server. This achieves several goals: it eases the load of the server because it doesn't need to serve all clients itself, and it improves performance by being closer to the client. In other words, it takes less time to transmit the resource back. For a web site, web caching is a major component in achieving high performance. However, the cache functionality must be configured properly, as not all resources stay identical forever: it's important to cache a resource only until it changes, not longer.
There are several types of caches. These can be grouped into two main categories: shared and private caches. A shared cache is a cache that stores responses for reuse by more than one user. A private cache is dedicated to a single user. This page will mostly talk about browser and proxy caches, but there are also gateway caches, CDN, reverse proxy caches and load balancers that are deployed on web servers for better reliability, performance and scaling of web sites and web applications.
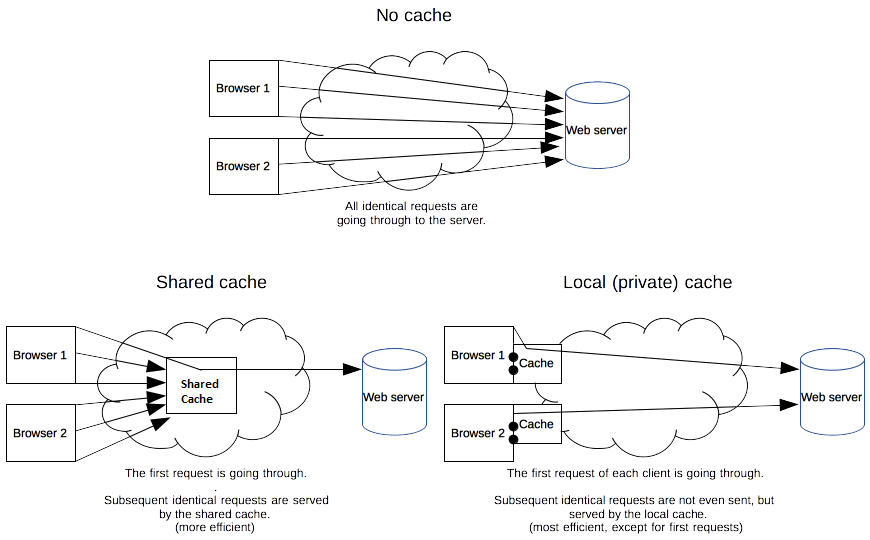
Private browser caches
A private cache is dedicated to a single user. You may have seen "caching" in your browser's settings already. A browser cache holds all documents the user downloads via HTTP. This cache is used to make visited documents available for back/forward navigation, saving, viewing-as-source, etc. without requiring an additional trip to the server. It also improves offline browsing of cached content.
Shared proxy caches
A shared cache is a cache that stores responses to be reused by more than one user. For example, an Internet Service Provider (ISP) or your company might have set up a web proxy as part of its local network infrastructure to serve many users so that popular resources are reused a number of times, reducing network traffic and latency.
Targets of caching operations
HTTP caching is optional but usually desirable. HTTP caches are typically limited to caching responses to the request method GET; they may decline other methods. The primary cache key consists of the request method and target URI (often, only the URI is used because only GET requests are caching targets).
Common forms of caching entries are:
- Successful results of a retrieval request: a
200(OK) response to aGETrequest containing a resource like HTML documents, images or files. - Permanent redirects: a
301(Moved Permanently) response. - Error responses: a
404(Not Found) result page. - Incomplete results: a
206(Partial Content) response. - Responses other than
GETif something suitable for use as a cache key is defined.
A cache entry may also consist of multiple stored responses differentiated by a secondary key if the request is target of content negotiation. For more details, see the information about the Vary header below.
Controlling caching
The Cache-Control header
The Cache-Control HTTP/1.1 general-header field is used to specify directives for caching mechanisms in both requests and responses. Use this header to define your caching policies with the variety of directives it provides.
No caching
The cache should not store anything about the client request or server response. A request is sent to the server and a full response is downloaded each and every time.
Cache-Control: no-store
Cache but revalidate
A cache will send the request to the origin server for validation before releasing a cached copy.
Cache-Control: no-cache
Private and public caches
The "public" directive indicates that the response may be cached by any cache. This can be useful if pages with HTTP authentication or response status codes that aren't normally cacheable should now be cached.
On the other hand, "private" indicates that the response is intended for a single user only and must not be stored by a shared cache. A private browser cache may store the response in this case.
Cache-Control: private Cache-Control: public
Expiration
The most important directive here is max-age=<seconds>, which is the maximum amount of time in which a resource will be considered fresh.
This directive is relative to the time that the response was sent by the server, and overrides the Expires header (if set).
Cache-Control: max-age=31536000
You can use a large max-age value for files that rarely or never change.
This might include images, HTML, CSS files, and JavaScript files.
For more details, see also the Freshness section.
Validation
When using the "must-revalidate" directive, the cache must verify the status of stale resources before using them. Expired resources should not be used. For more details, see the Cache validation section.
Cache-Control: must-revalidate
The Pragma header
Pragma is an HTTP/1.0 header. Pragma: no-cache is like Cache-Control: no-cache in that it forces caches to submit requests to the origin server for validation before releasing a cached copy. However, Pragma is not specified for HTTP responses and is therefore not a reliable replacement for the general HTTP/1.1 Cache-Control header.
Pragma should only be used for backwards compatibility with HTTP/1.0 caches where the Cache-Control HTTP/1.1 header is not yet present.
Freshness
Once a resource is stored in a cache, it could theoretically be served by the cache forever. Caches have finite storage space so items are periodically removed from storage. This process is called cache eviction.
Also, some resources may change on the server so the cache should be updated when this happens. As HTTP is a client-server protocol, servers can't contact caches and clients when a resource changes; they have to communicate an expiration time for the resource. Before this expiration time, the resource is fresh; after the expiration time, the resource becomes a stale resource.
Eviction algorithms often privilege fresh resources over stale resources.
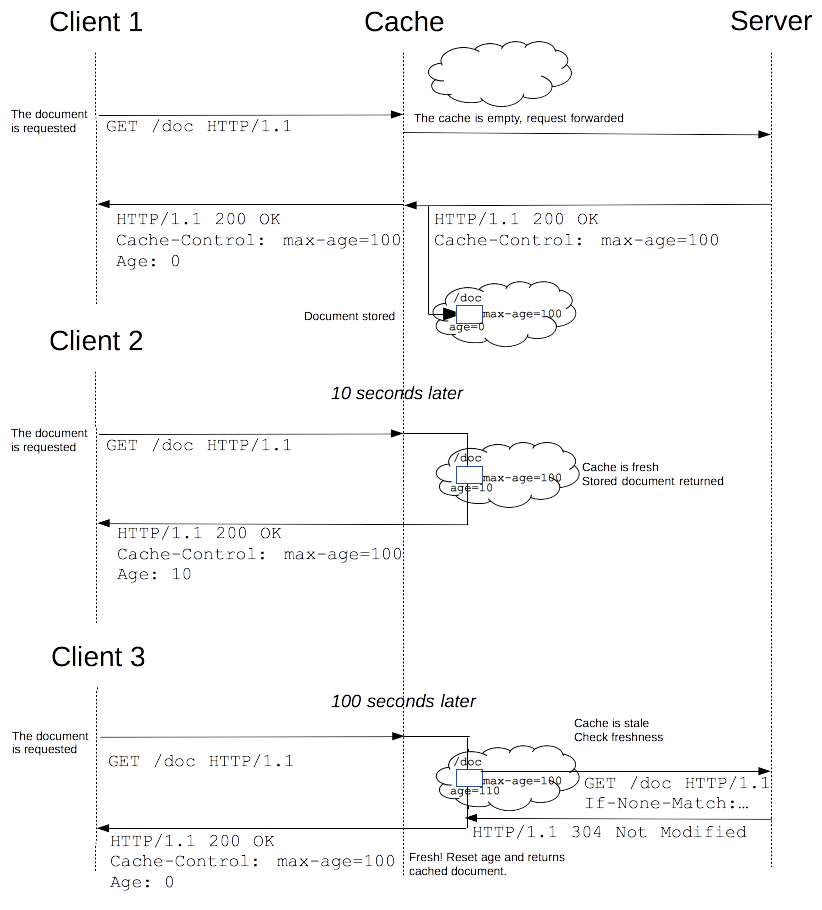
Note that a stale resource is not evicted or ignored; when the cache receives a request for a stale resource, it forwards this request with an If-None-Match header to check if it is in fact still fresh. If so, the server returns a 304 (Not Modified) header without sending the body of the requested resource, saving some bandwidth.
Here is an example of this process with a shared cache proxy:
Freshness lifetime
A response's freshness lifetime is the length of time between its generation by the origin server and its expiration time. The freshness lifetime for a response is calculated based on several headers:
- If the cache is shared and a
Cache-Controlheader with as-maxage=Ndirective is present, the freshness lifetime is N. - If a
Cache-Controlheader with amax-age=Ndirective is present, the freshness lifetime is N. - If an
Expiresheader is present, the freshness lifetime is its value minus theDateheader value. - Otherwise, no explicit expiration time is present in the response. A heuristic freshness checking approach might be applicable
For more information, see Calculating Freshness Lifetime in the HTTP specification.
Heuristic freshness checking
If an origin server does not explicitly specify freshness (for example, using a Cache-Control or Expires header), then a heuristic approach may be used.
If this is the case, look for a Last-Modified header. If the header is present, then the cache's freshness lifetime is equal to the value of the Date header minus the value of the Last-modified header divided by 10. The expiration time is computed as follows:
expirationTime = responseTime + freshnessLifetime - currentAge
where responseTime is the time at which the response was received according to the browser, and freshnessLifetime is the freshness lifetime.
For more information, see Calculating Heuristic Freshness in the HTTP specification.
Revved resources
The more we use cached resources, the better the responsiveness and the performance of a website will be. To optimize the use of cached resources, good practices recommend to set expiration times as far in the future as possible. This is possible for resources that are updated regularly or often, but it is problematic for resources that are updated rarely or infrequently. The latter are the resources that would benefit the most from caching resources, yet they are very difficult to update. This is typical of the technical resources included and linked from each webpages: JavaScript and CSS files change infrequently, but when they change you want them to be updated quickly.
Web developers invented a technique that Steve Souders called revving. Infrequently updated files are named in a specific way: in their URL, usually in the filename, a revision (or version) number is added. That way each new revision of the resource is considered a resource on its own that never changes and that can have an expiration time very far in the future, usually one year or even more. To get the new versions, all the links to the resources must be changed. That is the drawback of this method: additional complexity that is usually taken care of by the tool chain used by Web developers. When the infrequently changed resources change, they induce an additional change to resources that vary often. When the latter are read, the new versions of the former are also read.
This technique has an additional benefit: updating two cached resources at the same time will not lead to the situation where the outdated version of one resource is used in combination with the new version of the other one. This is very important when websites have CSS stylesheets or JS scripts that have mutual dependencies, meaning that they depend on each other because they refer to the same HTML elements.
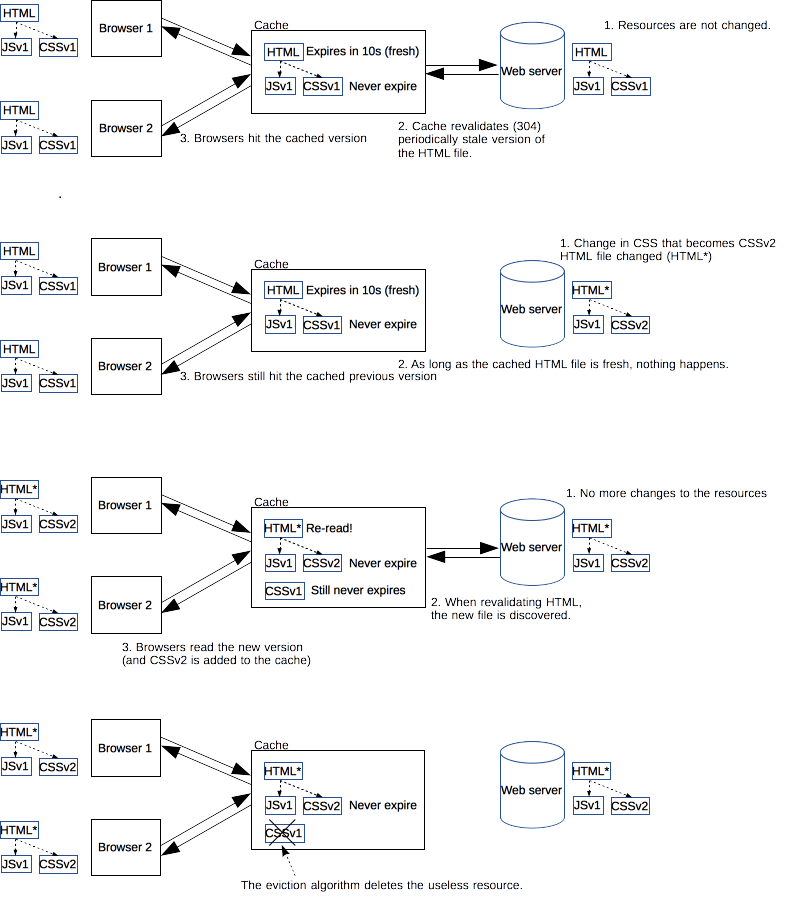
The revision version added to revved resources doesn't need to be a classical revision string like 1.1.3, or even a monotonously growing suite of numbers. It can be anything that prevents collisions, like a hash or a date.
Cache validation
When a cached resource's expiration time has been reached, the resource is either validated or fetched again. Validation can only occur if the server provided either a strong validator or a weak validator.
Revalidation is triggered when the user presses the Reload button. It is also triggered during normal browsing if the cached response includes the "Cache-Control: must-revalidate" header. You can also use the cache validation preferences in the Advanced->Cache preferences panel, which offers the option to force a validation each time a resource is loaded.
ETags
The ETag response header is an opaque-to-the-useragent value that can be used as a strong validator. That means that a HTTP user-agent, such as the browser, does not know what this string represents and can't predict what its value would be. If the ETag header was part of the response for a resource, the client can issue an If-None-Match in the header of future requests to validate the cached resource.
Last-Modified
The Last-Modified response header can be used as a weak validator. It is considered weak because it only has 1-second resolution. If the Last-Modified header is present in a response, then the client can issue an If-Modified-Since request header to validate the cached document.
When a validation request is made, the server can either ignore the validation request and respond with a normal 200 OK, or it can return 304 Not Modified (with an empty body) to instruct the browser to use its cached copy. The latter response can also include headers that update the expiration time of the cached resource.
Varying responses
The Vary HTTP response header determines how to match future request headers to decide whether a cached response can be used or a fresh one must be requested from the origin server.
When a cache receives a request that has a Vary header field, it must not use a cached response by default unless all header fields specified in the Vary header match in both the original (cached) request and the new request.
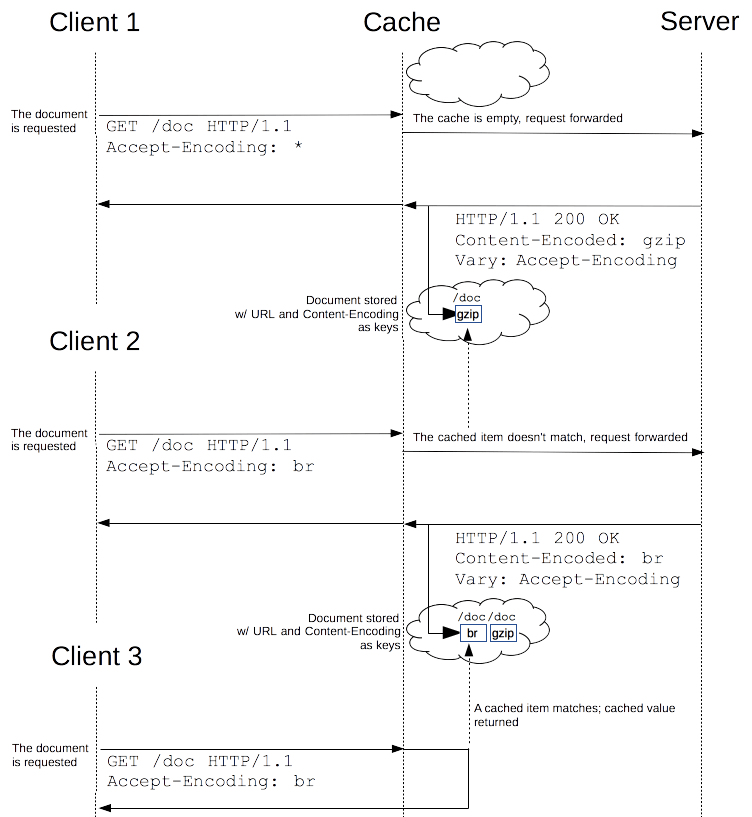 This feature is commonly used to allow a resource to be cached in uncompressed and (various) compressed forms, and served appropriately to user agents based on the encodings that they support. For example, a server can set
This feature is commonly used to allow a resource to be cached in uncompressed and (various) compressed forms, and served appropriately to user agents based on the encodings that they support. For example, a server can set Vary: Accept-Encoding to ensure that a separate version of a resource is cached for all requests that specify support for a particular set of encodings, for example, Accept-Encoding: gzip,deflate,sdch.
Vary: Accept-Encoding
Note: Use Vary with care. It can easily reduce the effectiveness of caching! A caching server should use normalization to reduce duplicated cache entries and unnecessary requests to the origin server. This is particularly true when you use Vary with headers and header values that can have many values.
The Vary header can also be useful for serving different content to desktop and mobile users, or to allow search engines to discover the mobile version of a page (and perhaps also tell them that no Cloaking is intended). This is usually achieved with the Vary: User-Agent header, and works because the User-Agent header value is different for mobile and desktop clients.
Vary: User-Agent
Normalization
As discussed above, caching servers will by default match future requests only to requests with exactly the same headers and header values. That means a request will be made to the origin and a new cache will be created for every slight variant that may be specified by different user-agents.
For example, by default, all of the following results in a separate request to the origin and a separate cache entry: Accept-Encoding: gzip,deflate,sdch, Accept-Encoding: gzip,deflate, Accept-Encoding: gzip. This is true even though the origin server will probably respond with — and store — the same resource for all requests (a gzip)!
To avoid unnecessary requests and duplicated cache entries, caching servers should use normalization to pre-process the request and cache only files that are needed. For example, in the case of Accept-Encoding, you could check for gzip and other compression types in the header before doing further processing, and otherwise unset the header. In "pseudo code" this might look like:
// Normalize Accept-Encoding
if (req.http.Accept-Encoding) {
if (req.http.Accept-Encoding ~ "gzip") {
set req.http.Accept-Encoding = "gzip";
}
// elseif other encoding types to check
else {
unset req.http.Accept-Encoding;
}
}
User-Agent has even more variation than Accept-Encoding. So if using Vary: User-Agent for caching mobile/desktop variants of files you'd similarly check for the presence of "mobile" and "desktop" in the request User-Agent header, and then clear it.
See also
- RFC 7234: Hypertext Transfer Protocol (HTTP/1.1): Caching
- Caching Tutorial – Mark Nottingham
- Prevent unnecessary network requests with the HTTP Cache – Jeff Posnick & Ilya Grigorik
- RedBot, a tool to check your cache-related HTTP headers.